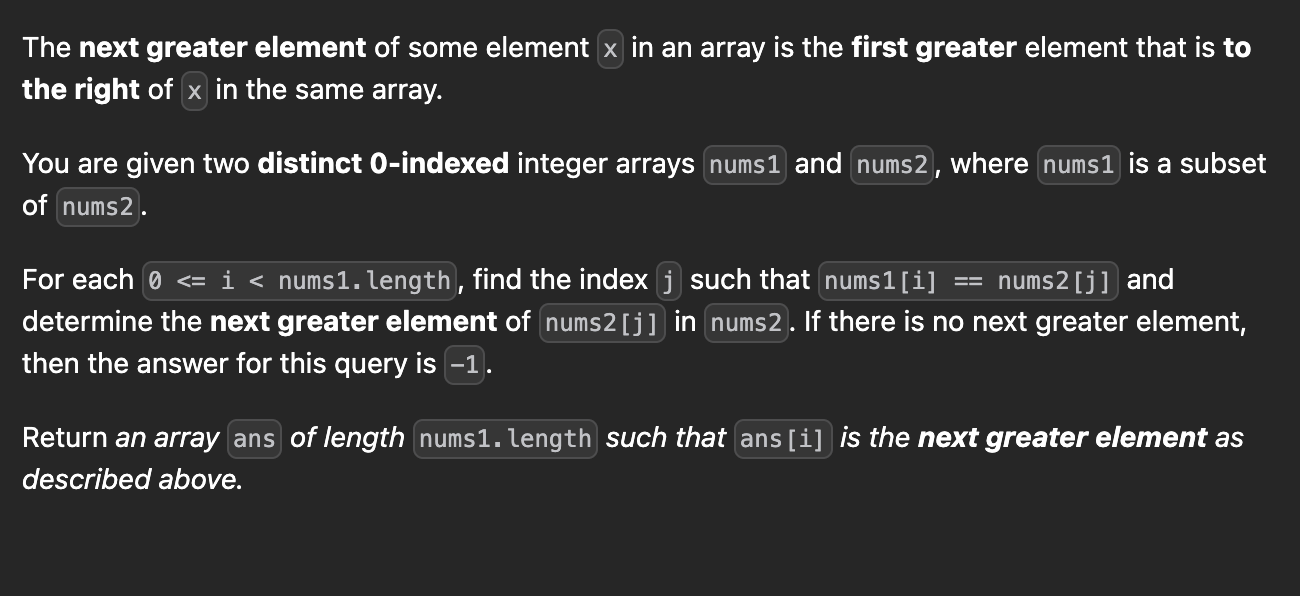
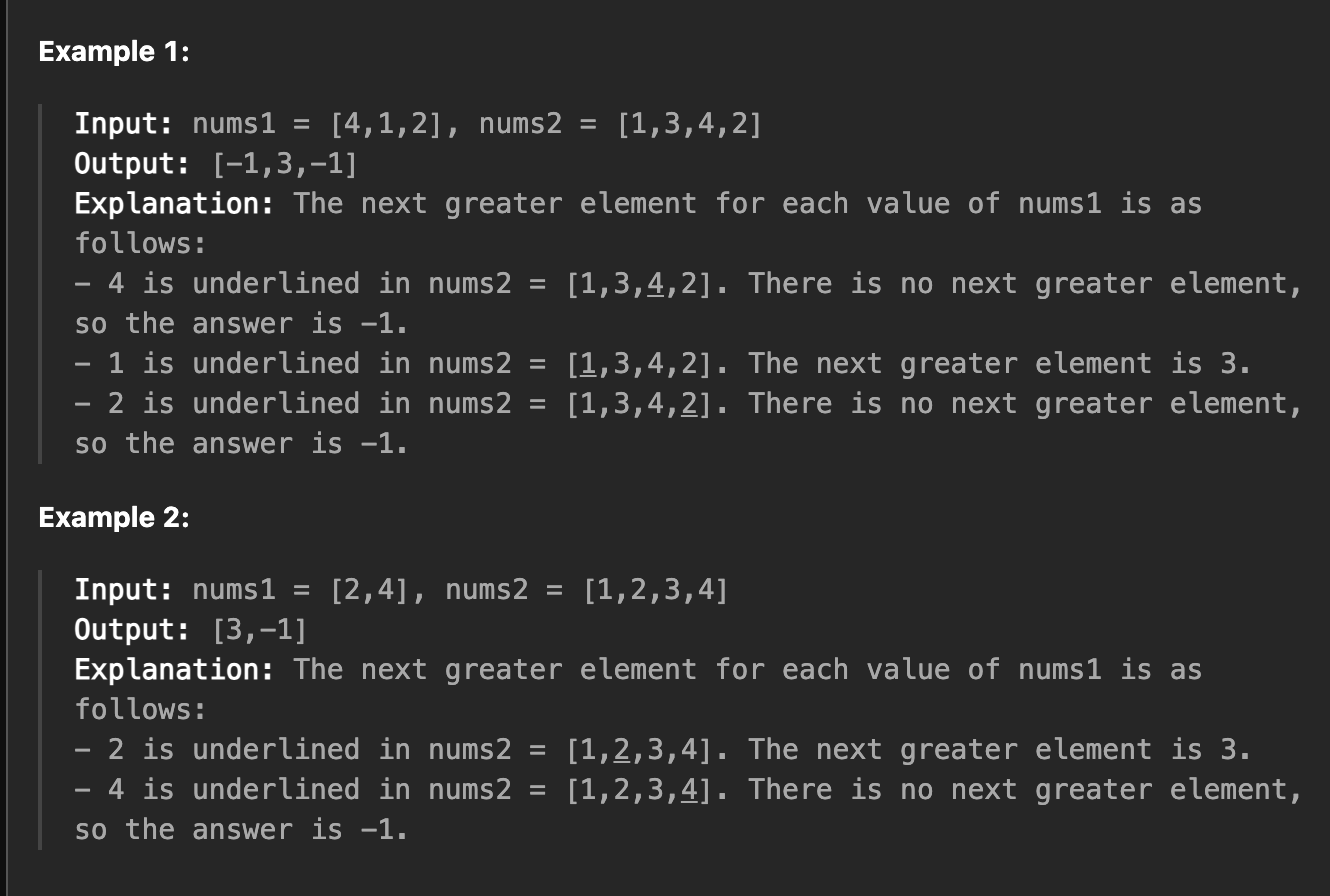
문제 :


두개의 리스트가 주어지고, 두개의 리스트 안의 같은 값의 인덱스에 대하여, 두 인덱스를 더한 값이 최소가 되는 값을 리스트에 넣어서 반환하는게 문제이다.
일단 보자 마자 해시 테이블이 생각났다. 처음에는 brute force로 이중 for문을 이용해 요소 하나하나씩 돌며 인덱스를 비교하려고 했으나, 리스트에서 원하는 값을 찾으려고 할때마다 검색비용 O(n)이 싫어 해시 테이블을 사용했다. 이 문제는 빈번하게 검색이 자주 일어나기 때문이다(다른 리스트에 현재 리스트에서 검색중인 값이 있나 확인).
아래는 내가 제출해 통과한 코드이다.
class Solution:
def findRestaurant(self, list1, list2):
l1 = {}
result = []
min_sum = float('inf')
for idx, item in enumerate(list1):
l1[item] = idx
for idx, item in enumerate(list2):
if item in l1:
current_sum = l1[item] + idx
if current_sum < min_sum:
result = [item]
min_sum = current_sum
elif current_sum == min_sum:
result.append(item)
return result
- 일단, 첫번째 리스트의 값들을 요소값 : 인덱스 쌍으로 매핑 시켜주었다. 두번째 리스트도 해시 테이블에 값을 매핑 시키려고 했으나 두번째 리스트는 굳이 매핑 할 필요가 없었다.
- min_sum이라는 변수는 비교를 위해 추가한 변수인데, float('inf')를 사용해 최댓값을 일단 넣어 주었다.
- 두번째 리스트를 하나씩 차례대로 순회하며 해시테이블에 그 값이 존재하는지 확인한다.
- 만약 존재한다면, 두 값의 인덱스를 더해 current_sum 안에 저장 해 준다.
- 그 다음, 방금 저장한 current_sum이라는 값이 min_sum보다 작은지 확인한다. 작다면, 결과 배열에 result = [item]을 하여 새로운 최솟값을 찾았을 때 결과 리스트를 초기화하고 새로운 요소를 추가한다. 즉, 현재의 최소 인덱스 합보다 더 작은 합을 찾았을 때 이전의 결과를 모두 지우고 현재의 요소로 새롭게 리스트를 초기화 한다.
하지만, example 3을 보면, 두 요소의 합이 1인 pair들이 2개가 있으므로[current_sum == min_sum](이 경우엔 두 요소를 모두 결과 배열에 추가 해준다.) 이때는 결과 배열 초기화가 아니라 .append를 이용해 배열에 끝에다가 더해준다.
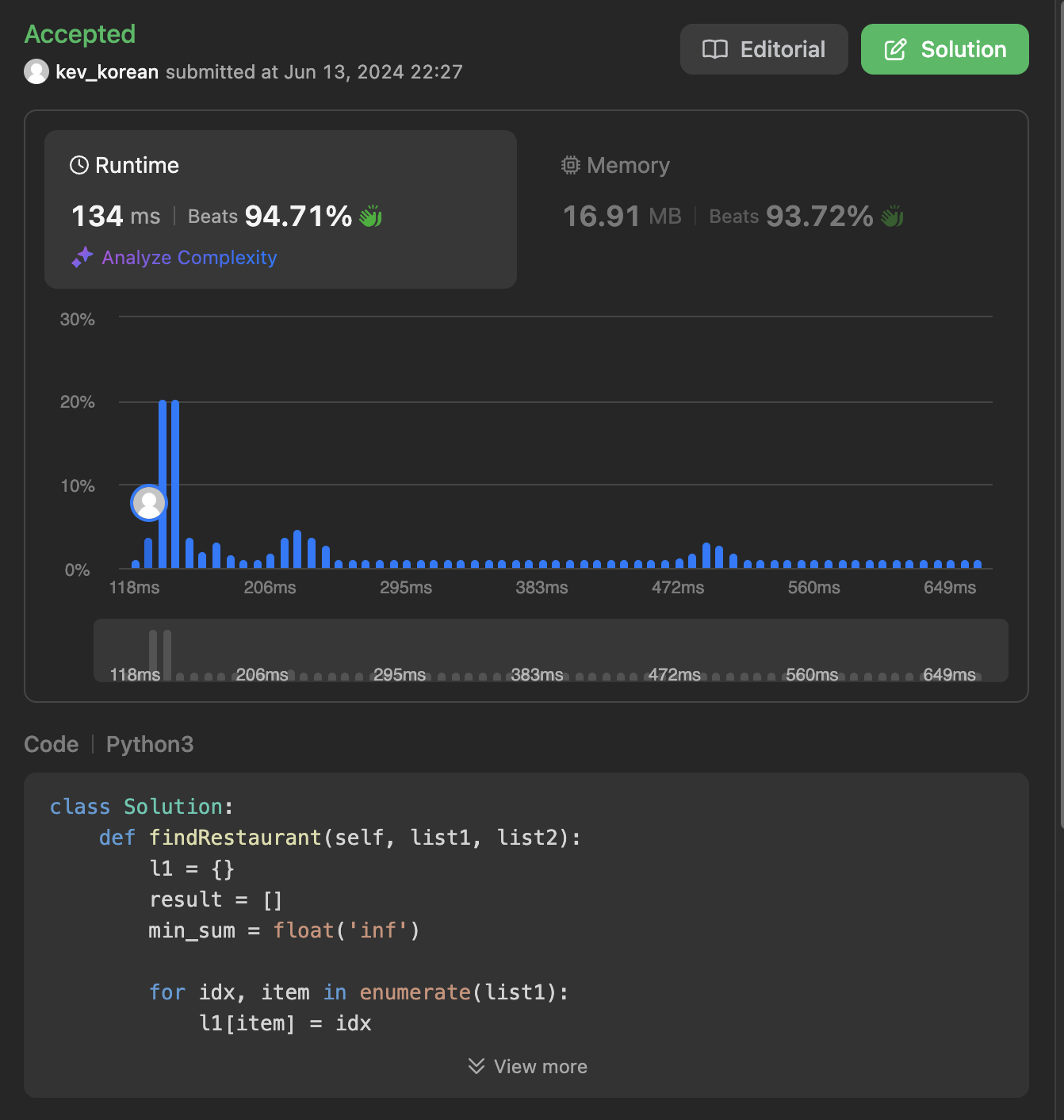
아래는 내가 받은 Runtime, Memory report이다.
- 새롭게 알게된 내용 & 기억할점 :
- `enumerate()` 함수는 반복문을 사용할 때 인덱스와 해당 인덱스의 요소를 동시에 얻을 수 있는 유용한 함수이다. 이를 사용하면 반복문 내에서 현재 요소가 몇 번째 요소인지 알 수 있으며, 코드의 가독성을 높이는 데 도움이 된다.
list1 = ["Shogun", "Piatti", "Tapioca Express", "Burger King", "KFC"]
for idx, item in enumerate(list1):
print(f"Index: {idx}, Item: {item}")
위 코드는 다음과 같이 출력된다:
Index: 0, Item: Shogun
Index: 1, Item: Piatti
Index: 2, Item: Tapioca Express
Index: 3, Item: Burger King
Index: 4, Item: KFC
사용 이유
`enumerate()` 함수는 인덱스와 요소를 동시에 다룰 수 있게 해 주므로, 다음과 같은 상황에서 유용하게 사용된다:
- 요소의 위치(인덱스)가 필요한 경우
- 인덱스를 사용하여 특정 조건을 체크하거나 조작할 때
- 코드의 가독성을 높이고 반복문 내에서 명확하게 인덱스를 참조하고자 할 때 - 문제를 다시 잘 생각하자. 내가 몇분동안 막혔던게 뭐였냐면, 맨 처음에는 조건문이 if current_sum < min_sum이면 곧바로 결과 배열에 값을 더했다. 하지만 생각해보면 이건 완전히 틀린 로직이다. 이렇게 되면, 처음 비교되는 값은 그 값이 최솟값이던 아니던무조건 결과 배열에 저장이 될 것이다. 예를들어, 첫번째 비교하는 대상의 두 인덱스의 합이 4이고, 두번째 비교하는 대상의 두 인덱스의 합이 1인 경우에도 결과 배열에는 [4, 1] 이렇게 저장이 될 것이다. 하지만, 이 문제의 목적은 "최솟값"을 찾는 것이다. 즉, 우리는 가장 작은 값만 찾으면 되므로, 배열에 현재 값을 임시로 저장해 두었다가 나중에 더 작은 값이 나오면 result = [item]으로 리스트의 내용을 교체해주면 된다.
- result = item은 적절하지 않다. 이 문장은 result를 리스트로 초기화하는 것이 아니라 item 값을 그대로 할당하는 것이다. result는 리스트로 유지되어야 하며, 이를 통해 여러 요소를 추가할 수 있어야 한다. 따라서 result = [item]이 맞는 표현이다.
다시 설명하자면, result = [item]은 result를 초기화하고 item을 새로운 리스트의 유일한 요소로 추가하는 역할을 한다. 반면에 result = item은 result를 리스트가 아닌 단일 값으로 설정하여 이후의 추가 작업을 불가능하게 만든다.
- `enumerate()` 함수는 반복문을 사용할 때 인덱스와 해당 인덱스의 요소를 동시에 얻을 수 있는 유용한 함수이다. 이를 사용하면 반복문 내에서 현재 요소가 몇 번째 요소인지 알 수 있으며, 코드의 가독성을 높이는 데 도움이 된다.
'CodingTest > Leetcode' 카테고리의 다른 글
| [LeetCode] #645. Set Mismatch (1) | 2024.06.18 |
|---|---|
| [LeetCode] #643. Maximum Average Array (0) | 2024.06.18 |
| [Leetcode] #506 Relative Ranks (1) | 2024.06.12 |
| [Leetcode] #500.Keyboard Row (1) | 2024.06.11 |
| [Leetcode]#496. Next Greater Element I (1) | 2024.06.07 |