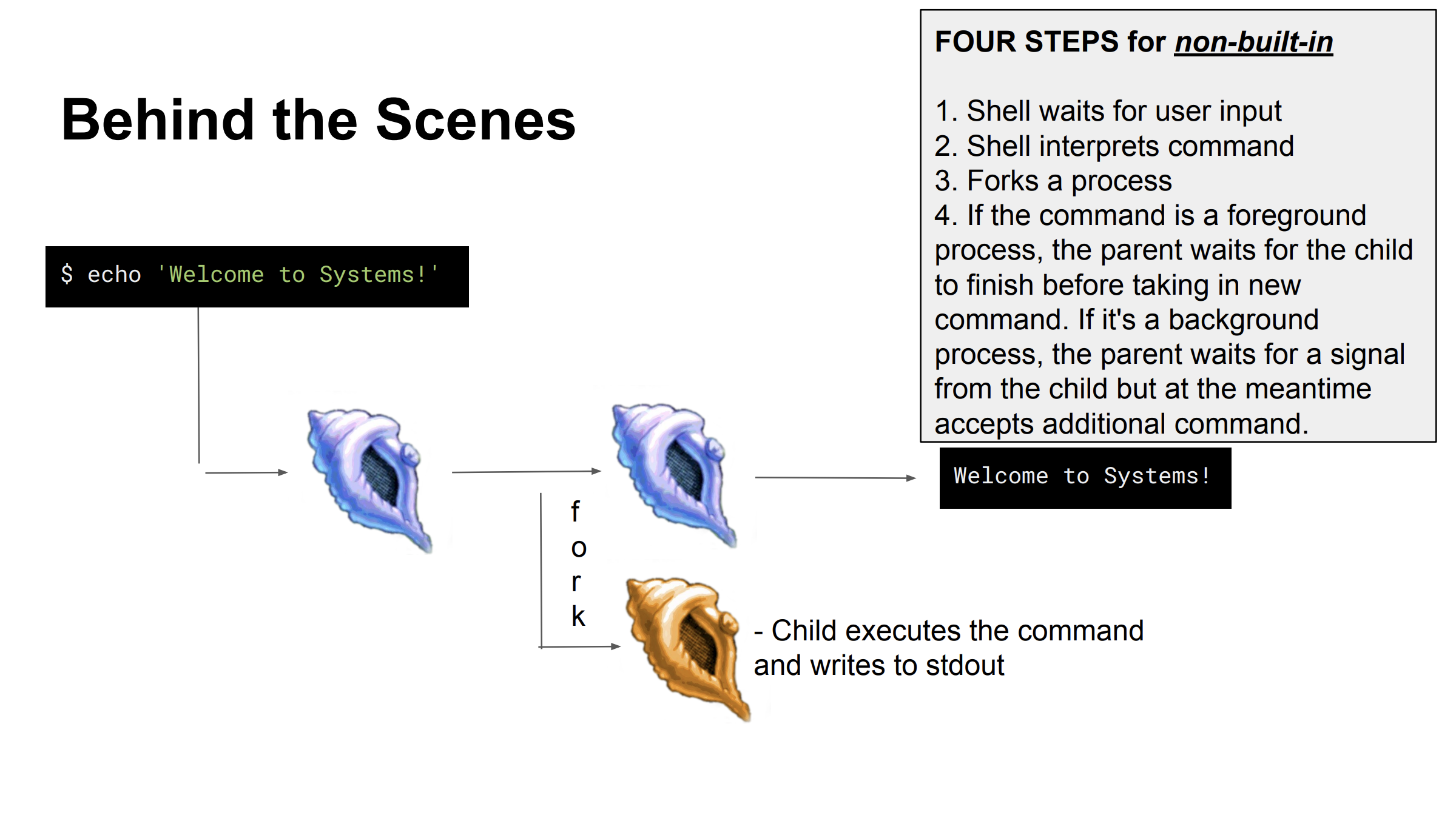
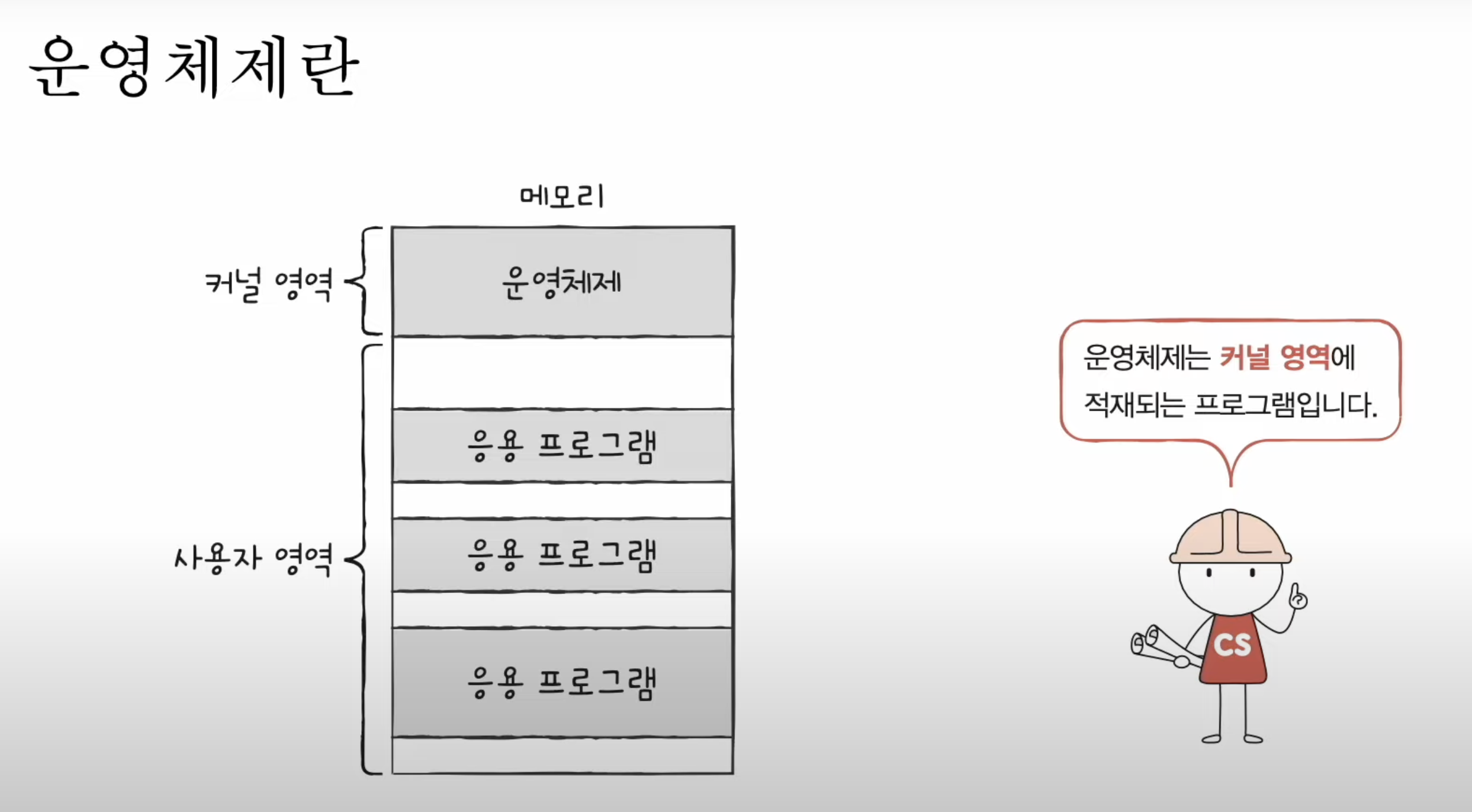
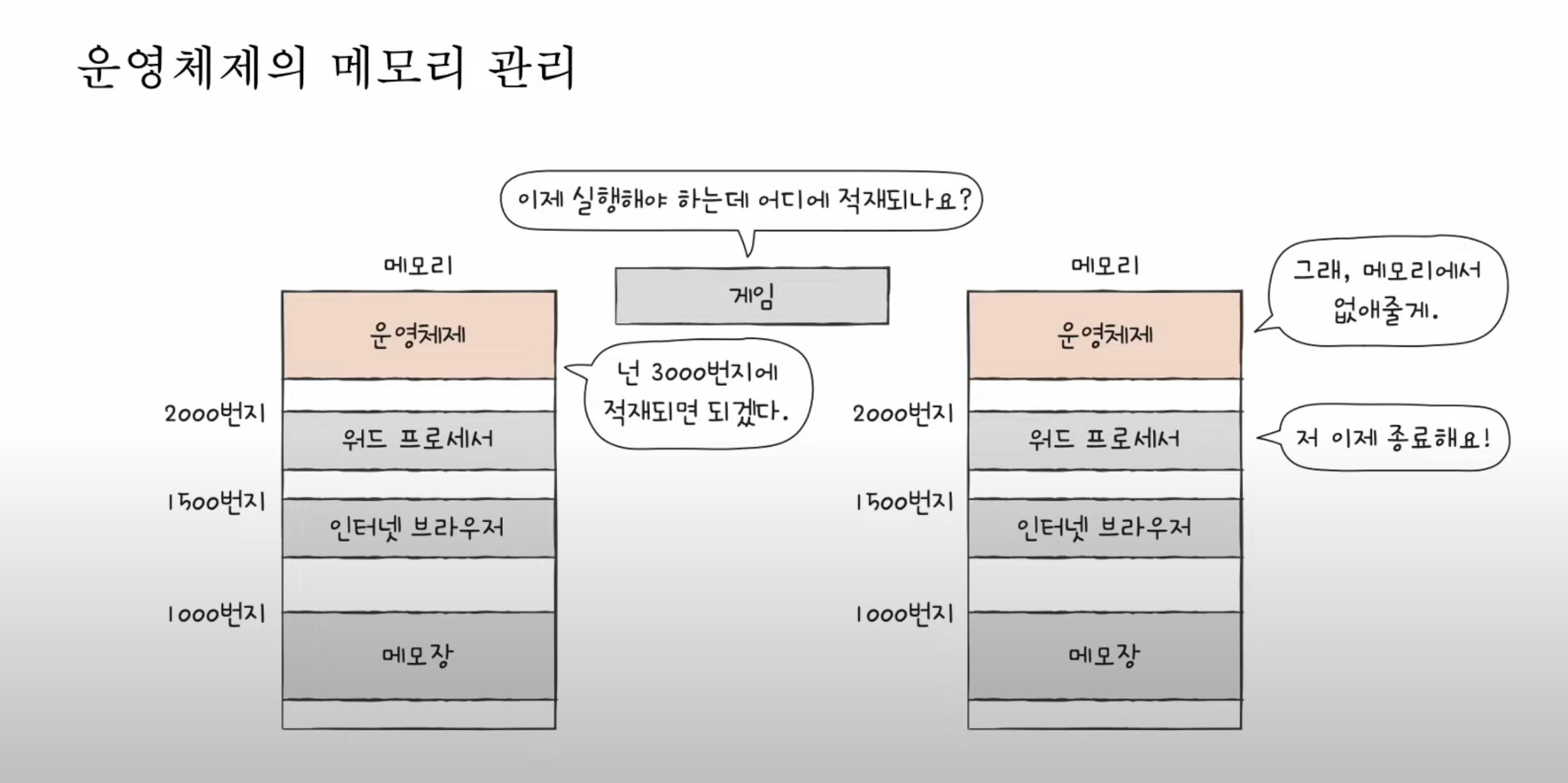
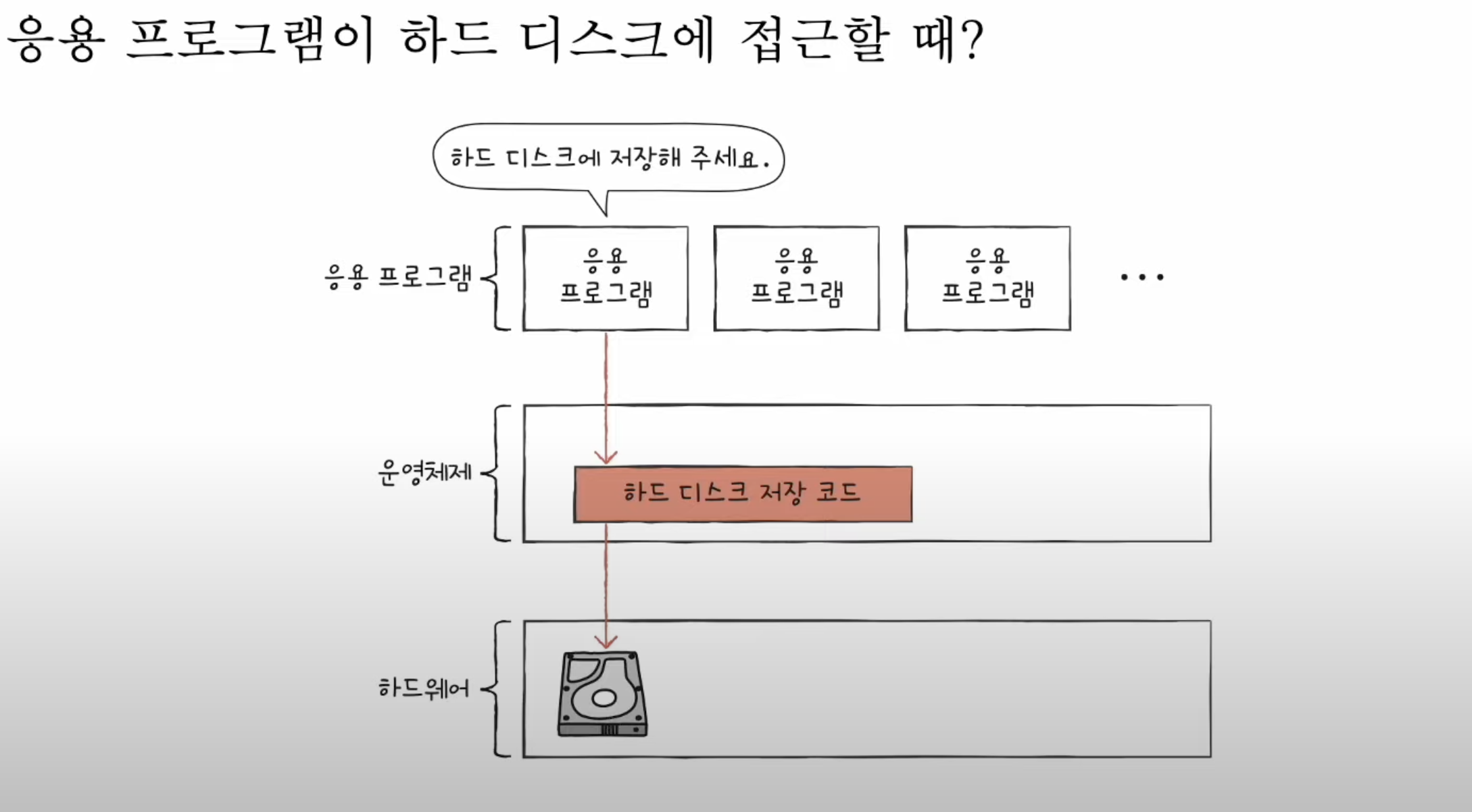
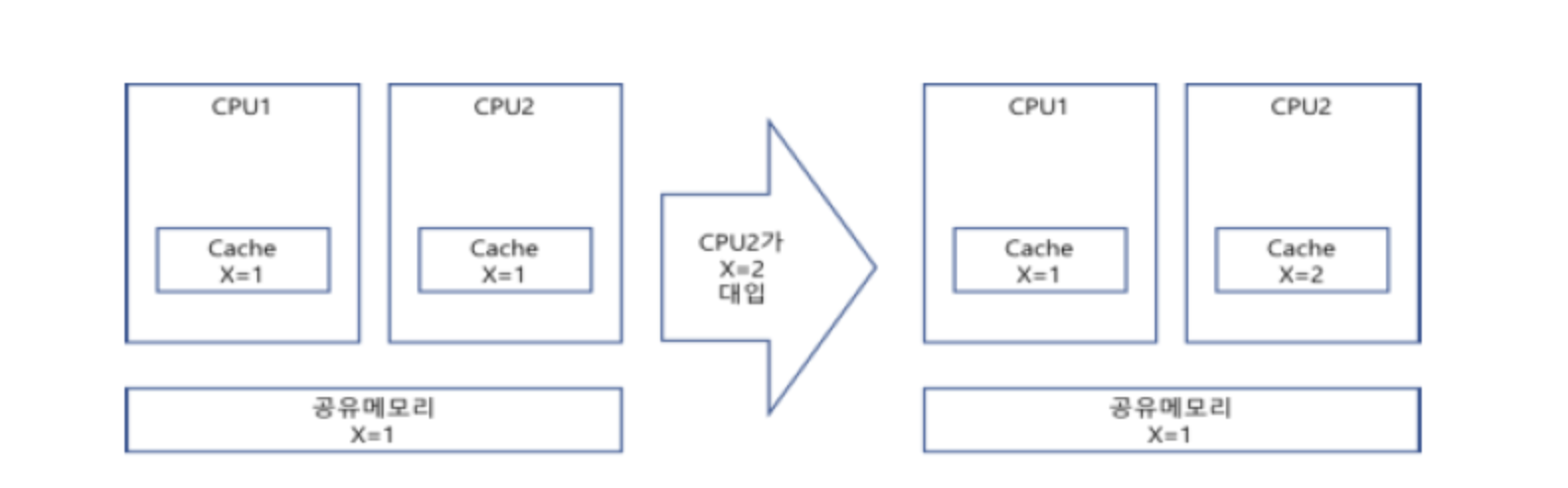
이전 포스팅을 보면 알겠지만, fork()를 통해 자식 프로세스를 생성하고(현재 자식 프로세스는 부모 프로세스의 속성들을 상속받은 상태, 즉 두개의 자식, 프로세스는 같은 일을 한다), exec()을 통해 자식 프로세스에게 새로운 자신만의 프로세스를 실행토록 했다.
posix_spawn은 fork()와 exec()을 완전히 대체하는 방법으로, 여러 프로세스를 if-else문으로 표현하는 대신 코드가 '선형'으로 구현된다.
※ I/O Piping
ls -l | grep *.txt | wc
주어진 명령어인 `ls -l | grep *.txt | wc`은 세 개의 명령어가 파이프(`|`)로 연결된 명령어다. 파이프는 한 명령어의 출력을 다른 명령어의 입력으로 전달하는데 사용된다(앞에 오는 명령어의 STDOUT이 파이프(' | ') 다음 명령어의 STDIN으로 연결된다). 이 명령어를 파이프의 관점에서 바라보자.
1. **ls -l:**
- `ls -l` 명령은 현재 디렉토리의 파일 및 디렉토리 목록을 나열한다.
- 이 명령의 출력은 터미널에 표시되고 파이프를 통해 다음 명령어로 전달된다.
2. **grep *.txt:**
- `grep *.txt` 명령은 `ls -l`의 출력에서 ".txt"로 끝나는 파일들을 찾아내어 출력한다.
- `grep`은 특정 패턴(여기서는 "*.txt")과 일치하는 라인을 찾아서 출력한다.
- 이 명령의 출력은 다시 파이프를 통해 다음 명령어로 전달된다.
3. **wc:**
- `wc` 명령은 입력으로 주어진 텍스트의 행 수, 단어 수, 문자 수를 세어 출력한다.
- 여기서는 `wc` 명령이 `grep` 명령의 출력을 받아서 파일(.txt로 끝나는 것들)의 행 수, 단어 수, 문자 수를 세어 출력한다.
파이프를 사용하는 경우, 각 명령어는 별도의 프로세스로 실행되며, 파이프로 연결된 명령어 간에는 프로세스 간 통신이 이루어진다. 아래는 파이프를 통해 명령어 간에 데이터가 어떻게 전달되고 fork가 발생하는지 간략한 설명이다.
1. **ls -l의 실행:**
- `ls -l` 명령이 실행되면 새로운 프로세스가 fork되어 해당 명령이 실행된다.
- 이 프로세스는 현재 디렉토리의 파일 및 디렉토리 목록을 출력한다.
2. **grep *.txt의 실행:**
- `ls -l` 명령의 출력이 파이프를 통해 `grep *.txt` 명령에 전달된다.
- `grep *.txt` 명령이 실행되면 또 다른 프로세스가 fork되어 해당 명령이 실행된다.
- 이 프로세스는 `ls -l` 명령의 출력에서 ".txt"로 끝나는 파일들을 찾아내어 출력한다.
3. **wc의 실행:**
- `grep *.txt` 명령의 출력이 파이프를 통해 `wc` 명령에 전달된다.
- `wc` 명령이 실행되면 또 다른 프로세스가 fork되어 해당 명령이 실행된다.
- 이 프로세스는 `grep *.txt` 명령의 출력을 받아서 행 수, 단어 수, 문자 수를 세어 출력한다.
이러한 과정을 통해 각 명령어는 '독립적인 프로세스'로 실행되며, 파이프를 통해 데이터가 전달되고, 각각의 명령어가 그 결과를 만든다.

※ I/O 리디렉션
- 리디렉션(Redirection)은 리눅스/유닉스 기반 운영 체제에서 프로세스의 입출력 방향을 변경하는 기능이다. 이를 통해 표준 입력(STDIN), 표준 출력(STDOUT), 표준 오류(STDERR)를 파일이나 다른 디바이스로 변경하거나 조작할 수 있습니다.
다음은 주요 리디렉션 기호들이다.
- `>`: 출력을 파일로 리디렉션한다. 기존 파일이 있으면 덮어쓴다.
- `>>`: 출력을 파일로 리디렉션한다. 기존 파일이 있으면 덧붙인다.
- `<`: 파일로부터 입력을 받아오는 리디렉션이다.
- `2>`: 표준 오류(STDERR)를 파일로 리디렉션한다.
- `2>>`: 표준 오류(STDERR)를 파일로 리디렉션하며, 기존 파일이 있으면 덧붙인다. - I / O 리디렉션(출력)

위는 'Welcome to Systems'라는 문자열을 output.txt로 리디렉션하여 output.txt에 문자열이 출력되도록 리디렉션을 한것이다.
- I /O 리디렉션(입력)
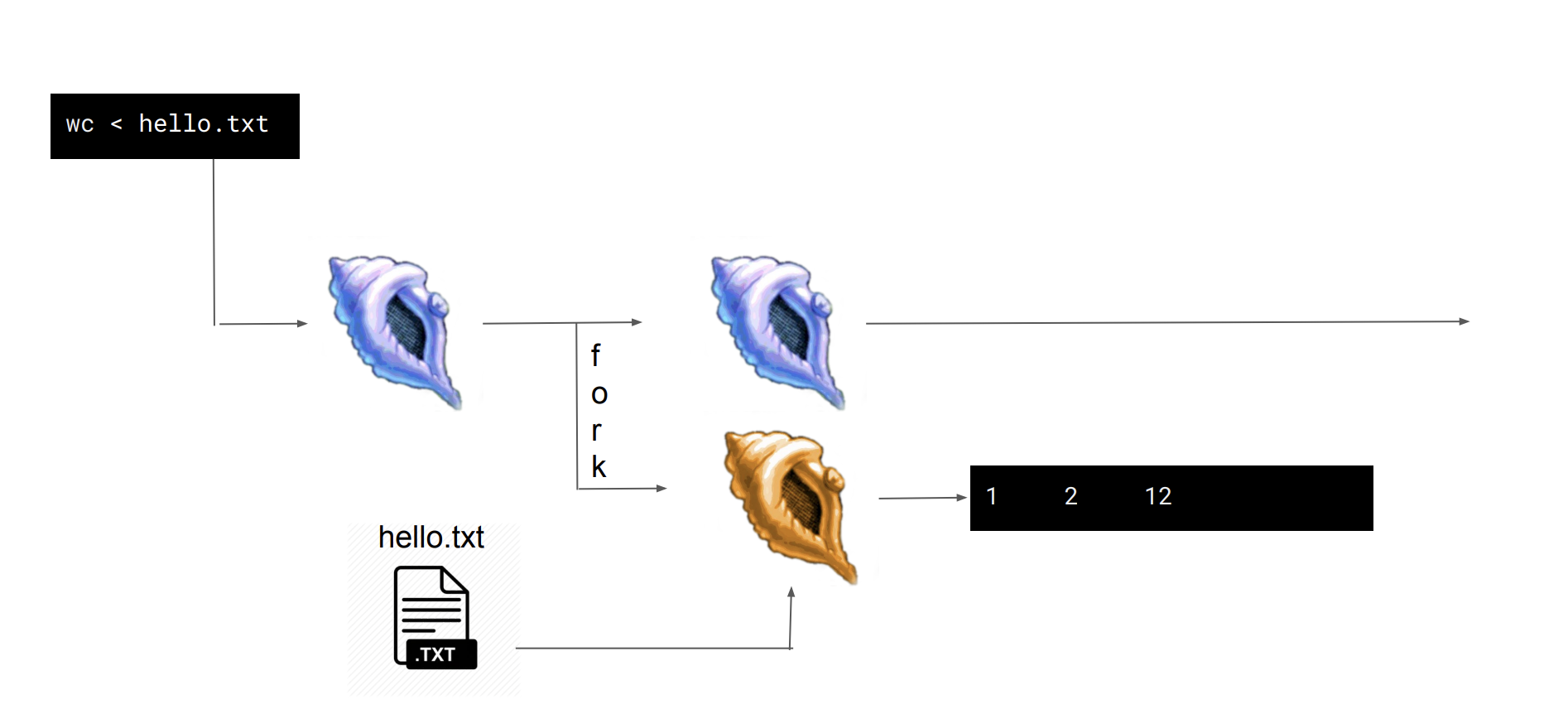
wc는 단어의 수를 세서 출력하는 커맨드인데, hello.txt로 리디렉션 하여 hello.txt를 입력값으로 받아 hello.txt의 word count를 출력한다.
※ Signal Handling
"신호(Signal)"는 프로세스에게 특정 이벤트나 조작을 알리는 비동기적인 이벤트다. 이러한 신호는 특정 상황이나 이벤트가 발생했을 때 프로세스에게 알려주어, 해당 프로세스가 특별한 동작을 수행하도록 한다.
Signal Handling은 주로 프로세스 간의 통신, 예외 처리, 프로세스 간 협력 등 다양한 상황에서 사용된다. 아래는 자주 쓰이는 신호이다.
예)
- SIGINT (Interrupt): Ctrl+C로 발생하며, 프로세스에게 중단을 요청한다.
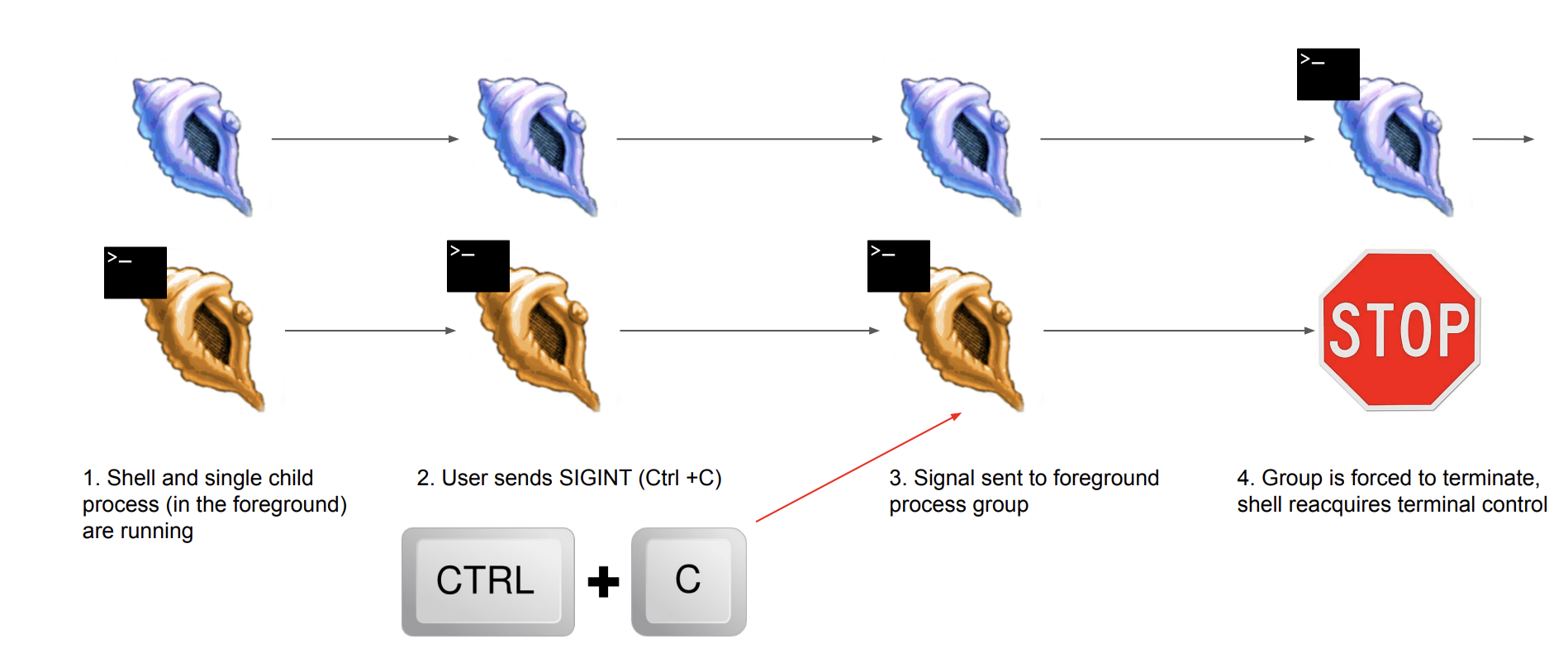
Signal Handling은 프로세스가 특정 신호를 받았을 때 어떻게 동작해야 하는지를 정의한다. 각각의 신호는 특정한 숫자로 식별되며, 이를 통해 운영 체제는 프로세스에게 어떤 신호가 발생했는지를 알린다.
프로세스는 특정 신호를 받았을 때 이에 대응하는 "시그널 핸들러(Signal Handler)"를 등록할 수 있다. 시그널 핸들러는 특정 신호를 받았을 때 실행되는 사용자 정의 함수로, 프로세스가 해당 신호를 처리하는 방법을 결정한다.
'컴퓨터 구조 + 운영체제(OS)' 카테고리의 다른 글
| [Linux] 셸이란 무엇이고, 셸은 어떻게 동작할까? (1) | 2024.02.07 |
|---|---|
| [Linux] 시스템 프로세스란? (1) | 2024.02.05 |
| [OS]프로세스 상태와 계층구조 (1) | 2024.02.01 |
| 운영체제 pt 1. 운영체제(Operating System)의 기초(System call) (0) | 2024.01.18 |
| 캐시 일관성(Cache coherence) (1) | 2023.12.05 |