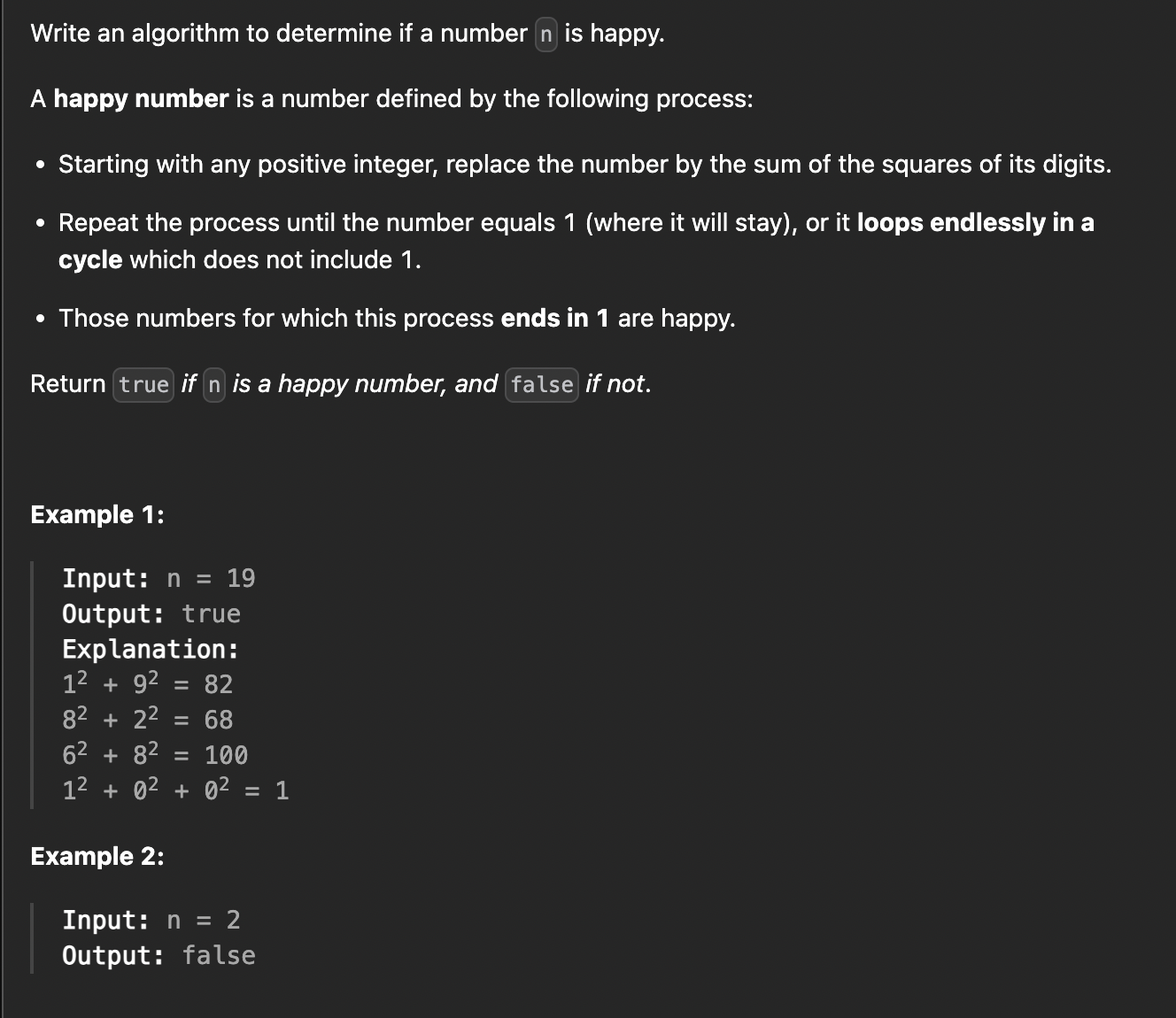
문제 :

이게 왜 easy인지 모르겠다. 이정도면 충분히 Medium 줄만도 한데...
먼저, 주어지는 파라미터는 2개이다.
1. 한개의 문자열
2. 여러개의 문자열들을 담은 리스트
일단 우리가 해야 할 일은, 문자열이 파라미터로 주어지고, 거기서 숫자나 공백이 아닌 영문 알파벳을 추출한 뒤, 두번째로 주어진 리스트에서 첫번째로 추출한 문자들이 등장하는지 확인하고, 등장한다면, 각 문자의 등장 횟수가 처음 주어진 문자열의 각 문자의 등장 횟수보다 적지 않으며, 마지막으로 그 중 길이가 가장 짧은 문자를 리턴하면 된다.
설명도 어렵다... 어쨌든 위 이미지의 설명과 예시를 본다면 문제 이해가 더 잘 될것이다.
먼저, 우리가 최종적으로 알아야 할 몇가지들부터 나열하면 우리가 쓸 알고리즘이나 자료구조를 좀 더 쉽게 파악 할 수 있을것이다.
요구사항:
1. 조건을 만족하면서 가장 짧은 문자열을 리턴.
2."각 문자의 등장 횟수가 처음 주어진 문자열의 각 문자의 등장 횟수보다 적지 않으며" 를 고려하면, 각 문자의 출현 횟수를 계속 tracking 하고 있어야 한다.
1. 로부터 내가 생각해낸 로직은 - 그렇다면, 두번째 파라미터로 주어진 여러 문자열을 담은 리스트들을 길이 순으로 정렬하면 어떨까?
그렇다면 첫번째 요소부터 조건을 비교 한 후, 모든 조건이 성립된다면 곧바로 리턴을 해버리고 끝내버린다. 예를들어, 리스트에 문자열들이 무작위 순서로 존재한다면, 처음부터 끝까지 모든 요소를 검사 한 후, 또 그중 가장 짧은 길이의 문자열을 리턴하는것은 너무 소모가 많다. 왜냐하면 아래 코드에서 보이겠지만, 문자 하나의 조건을 검사하는데 드는 비용은 O(n x m)이기 때문에 비싸다. 그렇기 때문에 모든 문자열을 검사하기 보단, 주어진 리스트의 문자열들을 문자열의 길이를 기준으로 정렬 한 후, 리스트의 첫 요소부터 차례로(이땐 맨 처음에는 가장 짧은 문자열이 들어가 있을 것이다.)
2. 로부터 내가 생각해낸 자료구조는 해시테이블(딕셔너리)이다. 먼저, 처음으로 주어진 문자열을 순회하며, 각 문자별로 등장 횟수를 값으로 매핑하여 딕셔너리에 저장한다. 위 이미지의 맨 처음 예시에서 딕셔너리의 모습은 dict = {s:2, p:1, t:1} 이다. 이후, 두번째 파라미터의 words에서 단어를 하나하나씩 꺼내와 별도의 해시 테이블에 같은 방식으로 출현 횟수와 함께 매핑시켜 준다.
위 이미지의 첫번째 예시의 첫번째 loop 을 보면 다음과 같다. 첫 단어는 step이고, 두번째 딕셔너리에는 {s : 1, p : 1, : t : 1}과 같이 담길 것이다(여기선 두 딕셔너리의 비교를 위해 첫 딕셔너리에 존재하지 않는 값은 두번째 딕셔너리에도 안 넣어줬다). 이렇게 두번째 딕셔너리에 모든 철자의 출현 횟수를 담아 준 뒤, 첫번째 딕셔너리와 두번째 딕셔너리를 비교하여 조건이 맞다면 그자리에서 바로 검사중인 단어를 리턴하고 끝내 버린다.
아래는 내가 제출해 통과한 코드이다.
class Solution:
def is_dict2_gte_dict1(self, dict1, dict2):
for key in dict1:
if dict1[key] > dict2.get(key, 0):
return False
return True
def shortestCompletingWord(self, licensePlate: str, words: List[str]) -> str:
dict1 = {}
lower = licensePlate.lower()
for i in lower:
if i.isalpha() and i in dict1:
dict1[i] += 1
elif i.isalpha() and i not in dict1:
dict1[i] = 1
alph = list(dict1.keys())
words.sort(key=len)
for word in words:
dict2 = {}
for i in word:
if i in alph and i in dict2:
dict2[i] += 1
elif i in alph and i not in dict2:
dict2[i] = 1
if self.is_dict2_gte_dict1(dict1, dict2):
return word
- 먼저, helper 메서드를 사용했다. is_dict2_gte_dict1 함수는 두개의 딕셔너리에 대하여 각 요소의 출현 횟수 범위가 범위를 벗어나는지 아닌지를 판별하는 메서드이다.
- 메인 함수로 들어와 빈 딕셔너리 dict1을 선언해주고 for문을 이용하여 등장하는 알파벳의 각 철자당 출현 횟수를 딕셔너리에 저장한다. 아 그리고 이 문제에서 대문자 소문자는 신경쓰지 않으므로 파이썬의 lower() 함수를 이용하여 문자열을 소문자로 바꿔주었다. 여기서 주의할점은 파이썬의 문자열은 리스트와 달리 불변의 객체이기 때문에 strings.lower()을 하면 원본 배열은 바뀌지 않고, 위의 코드와 같이 새로운 변수에 담아 주어야 한다.
- 그 후, 비교를 위해 추출해낸 알파벳들을 list(dict.keys())를 통해 리스트에 담아준다. 그리고 위에서 언급한 문자열의 길이대로 리스트를 정렬 해주기 위해 .sort() 메서드의 인자로 key = len을 넘겨주면 문자열의 길이를 기반으로 리스트를 오름차순 정렬 해준다. 이렇게 하면 가장 짧은 문자열부터 가장 긴 문자열대로 리스트가 정렬 될 것이다.
- 이제, words 리스트에서 문자열들을 하나씩 가져 올때마다 빈 딕셔너리를 선언 해주고, 그 문자열의 철자들을 하나하나씩 같은 방식으로 검사하여 두번째 딕셔너리(dict2)에 넣어준다. 여기서 if와 elif의 조건문을 잘 보면, 문자를 검사하면서 첫번째 딕셔너리 dict1에 존재하는 키값들만 넣어 주었다. 이렇게 해야 두 딕셔너리를 검사 하기가 수월하기 때문이다.
- 마지막으로, 헬퍼 메서드를 이용하여 조건이 맞는지 확인 한 후, 조건이 맞다면 return word를 통해 함수를 끝내 버린다.
아래는 내가 받은 report이다.

'CodingTest > Leetcode' 카테고리의 다른 글
| [LeetCode] #819. Most Common Word (0) | 2024.06.28 |
|---|---|
| [LeetCode] #804. Unique Morse Code Words (0) | 2024.06.27 |
| [LeetCode] #594. Longest Harmonious Subsequence (0) | 2024.06.25 |
| [LeetCode] #290. Word Pattern (0) | 2024.06.21 |
| [LeetCode] #205 Isomorphic strings (0) | 2024.06.21 |