[Leetcode] #349 Intersection of Two Arrays

엄청 간단한 문제이다. 2개의 배열이 파라미터로 주어지고, 두 배열에서 같은 값을 찾는것이다. 단, 같은 값들을 담은 리스트는 unique해야하며, 즉, 위의 예시처럼 [1,2,2,1]과 [2,2]의 겹치는 부분은 2개이지만(2,2), 결괏값은 [2]여야 한다.
엄청 간단한 문제이다. 뭔가 나도 문제를 보고 brute force가 생각나기 보단, "중복을 허용하지 않는다" 라는점에서 집합(Set)와 해시테이블을 생각했다.
- 집합은 중복을 허용하지 않으니, 먼저 리스트를 순회하며 빈 집합에 요소들을 차례로 넣고, 그 다음 두 집합의 교집합을 찾아내면 되지 않을까 생각했다.
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
set1 = set()
set2 = set()
for i in nums1 :
set1.add(i)
for j in nums2 :
set2.add(j)
return set1.intersection(set2)
1. set()를 이용하여 빈 집합을 각각 선언해준다.
2. 첫번째 인자로 주어진 nums1을 순회하며 집합에 넣어준다. 위의 예시에 경우엔 set1 = {1,2} 가 담길 것이다(중복 허용X).
3. 두번째 인자로 주어진 nums2를 순회하며 집합에 넣어준다. 위의 예시에 경우엔 set2 = {2}가 담길 것이다.
4. 파이썬의 집합 함수중, .intersection()을 활용해 교집합을 찾아낸다.
이렇게 간단한 코드이지만, 궁금증이 생겼다. 위 코드의 런타임은 아래와 같다.
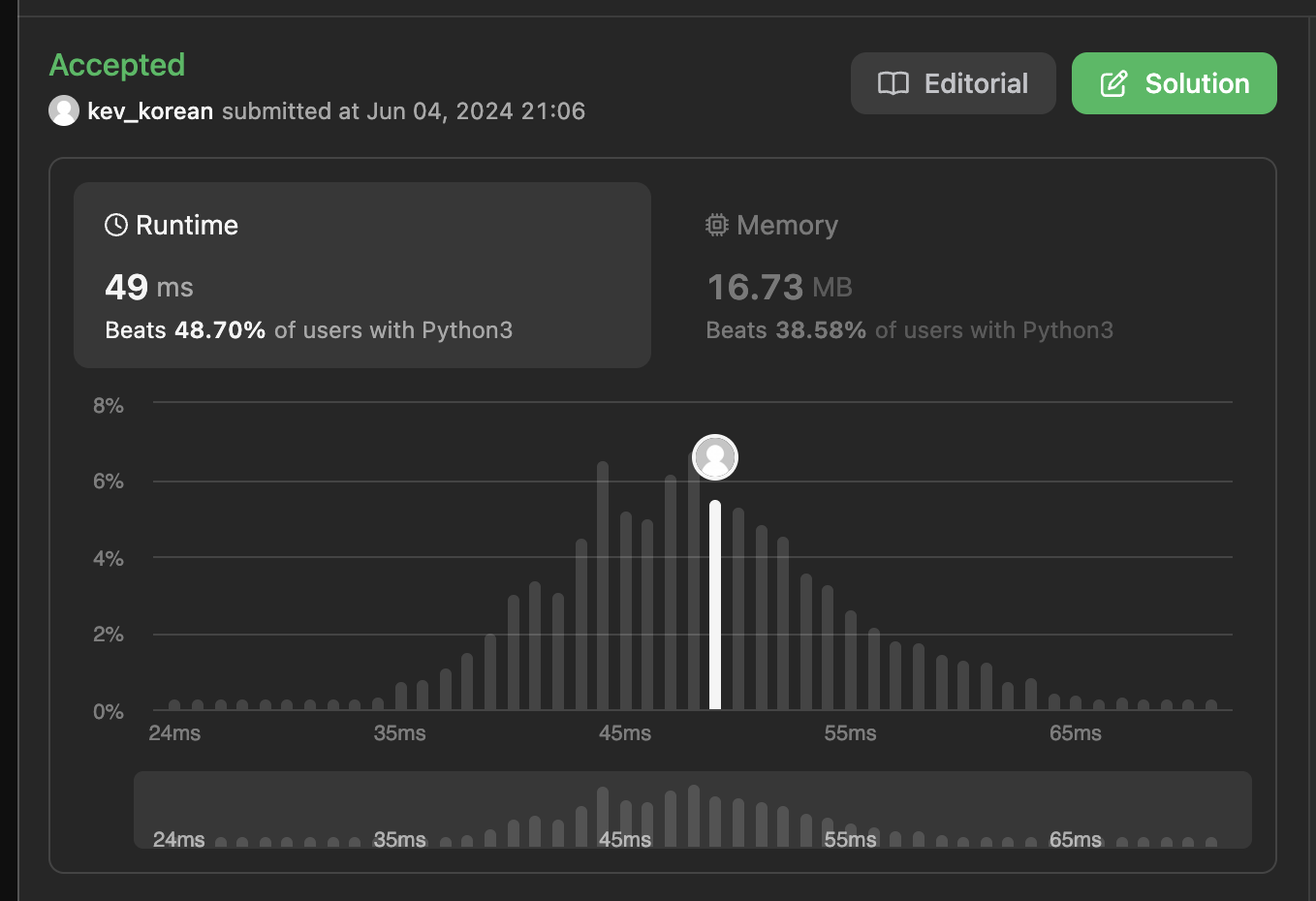
- 어떻게 더 런타임을 향상시킬 수 있을까?
제일 빠른 런타임을 가진 다른 사람의 솔루션은 아래와 같다.
class Solution:
def intersection(self, nums1: List[int], nums2: List[int]) -> List[int]:
set1=set(nums1)
set2=set(nums2)
inter=set1.intersection(set2)
return list(inter)
위의 솔루션이 나의 소스코드보다 런타임이 빠른 이유는 다음과 같다.
- set(nums1)와 set(nums2)는 각각의 리스트를 집합으로 변환한다. 이 변환은 한 줄의 코드로 이루어지며, 효율적으로 리스트를 순회하며 집합을 만든다.
- 궁금했던 점 : 근데 set()함수가 리스트를 순회하며 집합을 만드는것이라면, 내가 for문을 사용한것과 같은데 도대체 무슨 차이이지? 어차피 O(n)의 시간이 걸릴텐데...
- GPT 답변 :

이렇단다! 다음에 또 다시 파이썬의 집합을 써야 할때가 온다면 굳이 반복문을 통해 집합을 업데이트 하는 대신 내장함수를 사용할것!